
La robustesse des robots : un sens de l’adaptation à toute épreuve ?
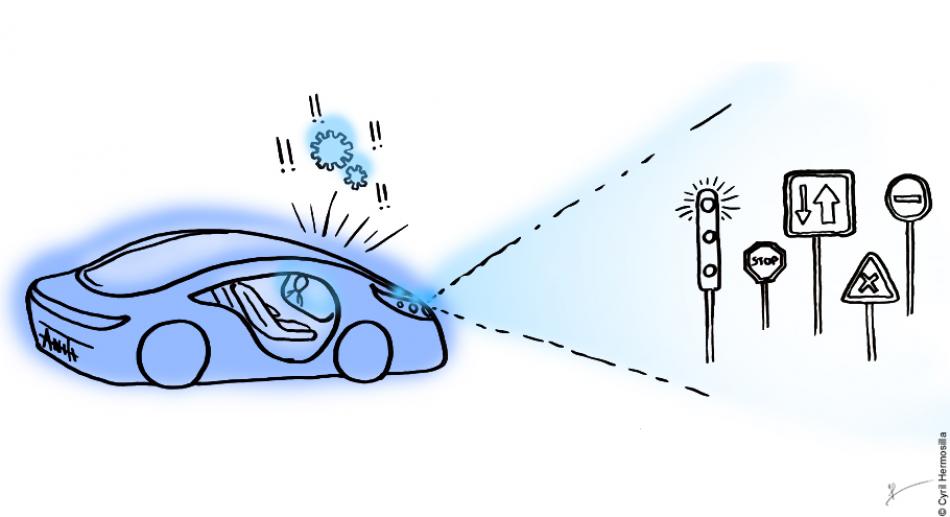
Lorsque l’on parle de voiture « robuste », le premier réflexe est d’observer la solidité du parechoc ou de la carrosserie… Mais en intelligence artificielle, la « robustesse » d’un véhicule autonome signifie qu’il s’adapte à des éléments imprévus de l’environnement dans lequel il évolue. Le système reconnaîtra un panneau, même partiellement caché derrière une branche ou un piéton.
Par Ewen Dantec, doctorant à l’Institut interdisciplinaire d’intelligence artificielle de Toulouse (ANITI - Artificial and Natural Intelligence Toulouse Institute) à l’INSA Toulouse, rattaché au laboratoire d’Analyse et d’Architecture des Systèmes (LAAS-CNRS)
Le fonctionnement d’une intelligence artificielle (IA) est comparable à celui d’un enfant. Tous deux apprennent à partir d’informations qui leur sont fourni. Puis ils appliquent ces enseignements à des situations et problématiques concrètes.
Admettons qu’on souhaite que le système d’IA d’une voiture autonome reconnaisse les panneaux stop. On va lui montrer des centaines d’exemples sous des angles et des éclairages différents. Puis on va le soumettre à une batterie de tests pour vérifier sa capacité à bien reconnaître ces panneaux.
C’est le moment de tester notre système d’IA sur la route… Mais au premier stop, catastrophe : la voiture autonome ne reconnaît pas le panneau stop et provoque un accident. Un autocollant était sur le panneau et l’IA n’a pas réussi à le reconnaître. Lors de la phase d’apprentissage de l’IA, aucun des panneaux présentés ne comportait d’autocollant. Confrontée à un exemple légèrement différent, l’IA n’a pas été capable de tirer la conclusion adéquate. Cette capacité de déduction à partir de données incomplètes ou biaisées, qui nous semble très naturelle, est en réalité mathématiquement difficile à obtenir.
Une IA « robuste » est capable de maintenir des performances satisfaisantes, même lorsqu’elle est confrontée à un environnement nouveau. Dans l’exemple précédent, elle aurait reconnu le panneau stop, malgré la présence de l’autocollant ou même s’il était dégradé par la rouille ou encore à moitié dissimulé derrière un arbre. Il existe bien des manières différentes d’altérer un panneau de signalisation au point qu’une IA ait du mal à le classifier. C’est là toute la difficulté de créer des systèmes autonomes robustes.
Entraîner l’IA à reconnaître des panneaux rouillés, cachés, abîmés…
La robustesse d’une IA dépend beaucoup de la qualité des données avec lesquelles elle a été entraînée lors de son apprentissage ou machine learning. Si elles sont fausses ou biaisées, l’IA reproduira les mêmes erreurs et les mêmes biais. Reprenons l’exemple de notre voiture autonome. Si nous lui avions montré uniquement des panneaux tâchés de rouille, le système n’aurait pu reconnaître que les panneaux rouillés.
Pour éviter ce problème, les données d’entraînement doivent être très volumineuses et diversifiées. Le but étant de confronter l’IA au maximum de variations possibles de son environnement pendant son entraînement. Certaines méthodes permettent d’adapter les algorithmes en les entraînant avec des données inédites, bruitées ou incomplètes. L’IA devient de plus en plus « robuste » en analysant, classifiant et mémorisant une diversité toujours plus grande de situations.
On peut également envisager de créer des IA capables d’apprendre en continu. À l’image de l’être humain, ces algorithmes apprendraient tout en travaillant. La voiture autonome pourrait améliorer sans cesse ses capacités de reconnaissance, en enregistrant tous les exemples de panneaux qu’elle croise.
Une telle approche a ses limites : personne ne voudrait d’une voiture inexpérimentée qui doit encore tout apprendre… Une vigilance humaine doit toujours vérifier que l’IA identifie et « étiquette » correctement les données recueillies, c'est à dire qu’elle appose le bon label sur une information. Autrement dit, il faut s’assurer qu’elle ne confonde pas un panneau stop avec un passant en imperméable rouge !
Illustration de Cyril Hermosilla


