
Discours politiques et expressions citoyennes : le poids des mots

Quel est le point commun entre la Révolution française, une campagne électorale, le mouvement des Gilets jaunes, une consultation citoyenne, un buzz sur les réseaux sociaux... ? Tous ces événements donnent lieu à des textes, écrits, oraux ou numériques, de dimensions parfois considérables. Ces événements, notamment lorsqu’ils se déroulent sur la Toile, peuvent impliquer une telle masse textuelle (plusieurs millions de mots) que les analyses « classiques » sont rendues impossibles.
Par Pascal Marchand et Pierre Ratinaud, enseignants-chercheurs, respectivement à l’Université Toulouse III – Paul Sabatier et à l’Université Toulouse – Jean Jaurès, effectuant leurs recherches au Laboratoire d’études et de recherches appliquées en sciences sociales (Lerass).
Au Laboratoire d’études et recherches appliquées en sciences sociales (Lerass), et avec le soutien du Labex SMS, un logiciel « libre » permet d’analyser, visualiser et interpréter ces données textuelles massives : Iramuteq, développé par Pierre Ratinaud, enseignant-chercheur au Lerass.
Il ne s’agit pas de faire des nuages de mots, qui n’ont aucune valeur descriptive et ne permettent pas d’analyse rigoureuse. Il ne s’agit pas non plus d’intelligence artificielle qui développe des algorithmes complexes pour concevoir des systèmes experts. Il s’agit de méthodes statistiques finalement assez classiques, appliquées à des tableaux de données assez simples, mais dont les dimensions sont considérables (jusqu’au milliard de cases).
Pourquoi cherchons-nous à analyser autrement des textes ?
Parce que les choix de mots ne sont pas aléatoires. Les représentations qui circulent à propos d’un phénomène social (par exemple une campagne électorale, un mouvement contestataire, des débats parlementaires, …) s’expriment dans et par le discours. On se souvient par exemple que Victor Klemperer relevait les mots caractéristiques de la rhétorique nazie à mesure qu'ils apparaissaient dans les discours officiels, les documents administratifs, les affiches, les blagues populaires… Dans le cadre d’enquêtes ou d’analyses d’archives, on se demandera donc pourquoi, dans l’univers des mots possibles, ce sont ceux-là qui ont été choisis et quelles relations ils entretiennent entre eux et avec leurs conditions de production. On postule donc que certains mots ont, selon les individus, les groupes ou les contextes, une probabilité d’occurrence plus forte que d’autres. Ce qui nous conduit à envisager l’approche statistique.
Comment ça marche, la textométrie ?
Quel que soit le terme employé : analyse (statistique) des données textuelles, lexicométrie, textométrie, logométrie… les questions restent les mêmes et ont été résumées par Ludovic Lebart et André Salem (1994) : « Quels sont les textes les plus semblables en ce qui concerne le vocabulaire et la fréquence des formes utilisées ? Quelles sont les formes qui caractérisent chaque texte, par leur présence ou leur absence ? ». Il s’agit donc de construire des grands tableaux croisant des textes et des formes (mots simples ou composés, fléchis ou réduits, bruts ou étiquetés, etc.). Ces méthodes conduisent alors à une compression de ces données multidimensionnelles, au prix assumé d’une perte d’information.
Caractériser les discours politiques sur les réseaux sociaux
Parmi ces méthodes, l’analyse factorielle des correspondances (AFC) est sans doute la première à s’être imposée. Sur un tableau qui croise les mots et les textes, il s’agit de déterminer quelles sont les grandes oppositions ou « facteurs » et de les représenter sous forme de cartes.
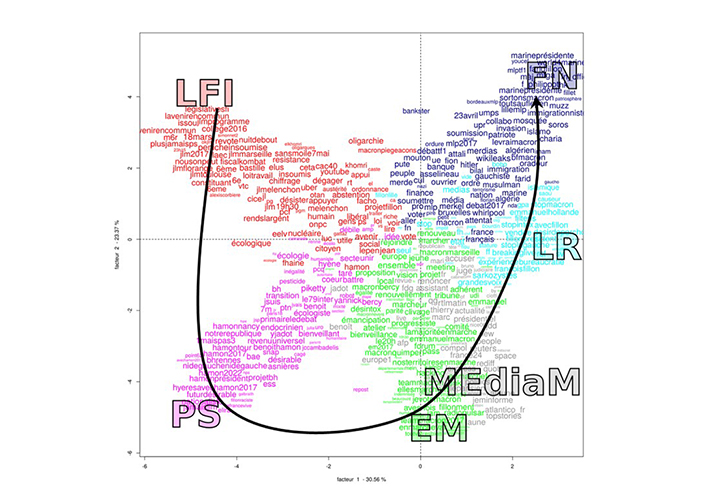
Lors de la campagne pour l’élection présidentielle de 2017, nous avons étudié les échanges sur Twitter au sein des communautés des cinq principaux candidats qui ont réuni plus de 90 % des suffrages au premier tour : Jean-Luc Mélenchon (LFI), Benoît Hamon (PS), Emmanuel Macron (EM), François Fillon (LR) et Marine Le Pen (FN). Nous avons ajouté à ce corpus les comptes des principaux médias. Les données extraites représentent 4,5 millions de tweets pour 70 millions d’occurrences (pour se faire une idée, imaginons que cela représente 87 fois la Bible). L’AFC représentée par la figure ci-dessous montre une organisation en « parabole » (LFI, PS, EM, LR, FN), selon un effet statistique connu sous le nom « d’effet Guttman » qui rend compte d’une organisation hiérarchique des lexiques politiques. Par le lexique qu’ils emploient, les internautes reproduisent donc l’organisation droite-gauche traditionnelle. En Marche ! occupe une position centriste avec un lexique qui se situe à proximité de celui des médias « mainstream ». Si les leaders du mouvement voulaient échapper au clivage droite-gauche, les internautes, eux, le rétablissaient.
Un regard nouveau sur des archives anciennes
Autre méthode originale : la classification descendante hiérarchique, développée par Max Reinert. Plutôt que de cartographier, il s’agit ici de définir statistiquement les différentes classes de lexique qui structurent un corpus textuel.
Récemment, nous avons utilisé Iramuteq pour analyser les discours de l’Assemblée nationale révolutionnaire de juin 1789 à janvier 1794. Ce corpus, dont la numérisation a fait l’objet d’une collaboration entre les bibliothèques de l’Université de Stanford et la Bibliothèque nationale de France (https://frda.stanford.edu/fr), représente environ 43 millions de mots (53 fois la Bible). Après un travail linguistique et historique d’homogénéisation des codes et des transcriptions, la classification lexicale automatique permet, non seulement de définir les thématiques qui structurent la naissance de la République, mais également d’en restituer la chronologie.
On retrouve ainsi des figures illustres de la Révolution française, mais on découvre d’autres personnages, beaucoup moins connus, et qui ont joué un rôle majeur. Par le nombre de mots prononcés, Robespierre arrive en 10ème position derrière Delacroix, Thuriot, Cambon, Camus, Démeunier, Lanjuinais, Barère, Merlin de Thionville et Basire.
Il en est de même pour les thèmes. Bien sûr, le procès du roi apparaît. Mais on montre également le travail législatif d’organisation de la nouvelle société française (la justice, l’armée, l’économie, les territoires). La statistique textuelle distingue très bien les trois assemblées Constituante, Législative et Conventionnelle. Et, contrairement à ce que qu’on a parfois pu penser, le discours complotiste qui annonce la Terreur apparaît assez tardivement.
Cette application, qui ouvre des perspectives d’analyse de nombreux corpus d’archives, représente une opportunité pour ce qu’on appelle aujourd’hui les humanités numériques.

Apporter sa pierre à l’édifice dans les grands débats publics
Grand débat sur l’identité nationale, Grand débat national… Finalement, qu’y avait-il dans ces consultations gouvernementales en ligne ? La question des distances entre les textes est une troisième tradition de l’analyse des données textuelles. Il s’agit de cartographier un gros corpus en fonction des distances entre les textes qui le composent.
Cette méthodologie nous a permis de cartographier le « Vrai débat », consultation citoyenne parallèle au Grand débat national, mise en place par un groupe de Gilets jaunes et qui représentait 119 000 textes et 7 millions d’occurrences (8,7 fois la Bible).
Le graphique suivant ressemble à un nuage de mots, mais ce n’est pas un nuage de mots. La différence est, qu’ici, la place, la taille et les liens des mots ont un sens statistique : ils traduisent des distances et des attractions dans des structures lexicales.
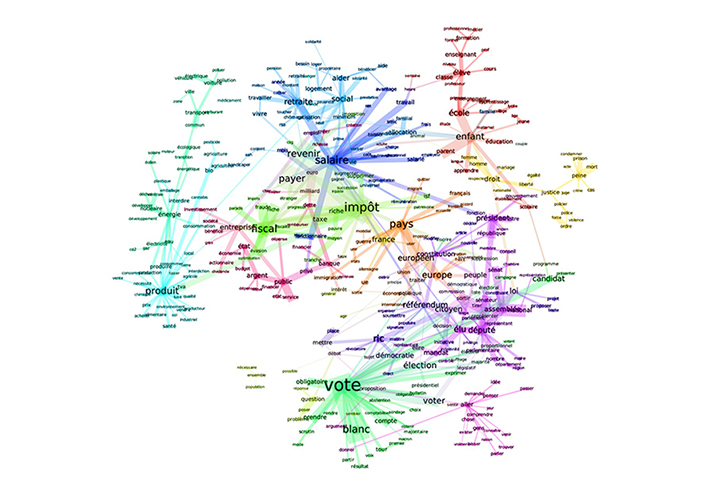
On peut y lire les différentes thématiques et leur structuration autour de noyaux qui font sens : propositions politiques (instaurer le RIC, compter le vote blanc, contrôler le travail parlementaire), économiques (redistribuer les ressources, contrôler les banques, repenser la fiscalité) et même écologiques (développer les énergies renouvelables et les circuits courts). On le voit, l’opposition entre « la fin du mois et la fin du monde » était sans doute une bien jolie formule médiatique, mais elle n’avait pas de réalité dans le débat des Gilets jaunes.
L’expertise textométrique peut donc suivre l’événement, l’éclairer et, dans le meilleur des cas, participer au débat public en y introduisant nos préoccupations scientifiques.
L’interdisciplinarité face à la masse de données médiatiques
L’évolution des outils de numérisation, l’accès à des bases de données toujours plus riches notamment sur Internet, amènent à constituer des corpus de plus en plus grands. En cinquante ans, des 60 000 occurrences des « tracts de mai 68 » on est passé, par exemple, aux 238 000 000 d’occurrences du « Cablegate » (les 251 287 câbles de la diplomatie américaines mis en ligne par le site WikiLeaks). Des événements exceptionnels, tant par leurs enjeux que par leur retentissement, sont apparus sous la forme de débats et consultations de citoyens. Les explorations textométriques permettent de porter un regard d’expert sur ces questions qui mobilisent un grand nombre de commentateurs et de médias d’information.
Le regard des sciences humaines et sociales mobilise alors l’outillage des sciences et techniques. L’opposition, classique entre des méthodes « quantitatives » et des méthodes « qualitatives » se trouve de fait questionnée, s’agissant d’outils de mesure des productions discursives. Si cela peut brouiller certains repères, c’est aussi une occasion de penser autrement la production de connaissances scientifiquement solides et socialement utiles.
Et dans ces entreprises scientifiques et citoyennes, le logiciel opensource aura certainement un rôle à jouer : des réseaux se constituent déjà autour de pôles universitaires pour produire des outils collaboratifs performants et librement accessibles. L’accès libre aux procédés permet, non seulement aux développeurs de comprendre les outils et de collaborer pour les faire évoluer, mais aussi et surtout d’être au plus près des demandes des utilisateurs en fonction de leurs corpus et de leurs hypothèses.
Références bibliographiques
- Marchand, P. & Ratinaud, P. (2012). Être français aujourd’hui. Les mots du « grand débat » sur l’identité nationale. Paris : Les Liens qui Libèrent.
- Marchand, P. & Ratinaud, P. (2017). Entre distinctivité et acceptabilité: Les contenus des sites Web de partis politiques. Réseaux, 204 (4), 71-95. URL : http://www.cairn.info/revue-reseaux-2017-4-page-71.htm
- Marchand, P. & Ratinaud, P. (2020). Analyser un corpus hétérogène : le cas des Archives numériques de la Révolution française. 15èmes Journées internationales des données textuelles (Toulouse). En ligne : http://lexicometrica.univ-paris3.fr/jadt/JADT2020/jadt2020_pdf/MARCHAND_RATINAUD_JADT2020.pdf


